Those actions described in that section are generated by an RL agent, used only for training. For the prediction and therefore results they still either check for aggregate metrics (which must use synthetic data in order to get enough of it), or do the MTurk comparison that generated up to 3 second clips which could in theory be created from real-time user input but since they have corresponding ground-truth frames it must at best be generated from sampled user input from a real gameplay session.
The clips they show on the YouTube video seem to have some interactive input, but the method for creating those is not described in the paper. So I suppose it is possible that there’s some degree of real time user input, but it’s not clear that it is in fact what’s happening there.
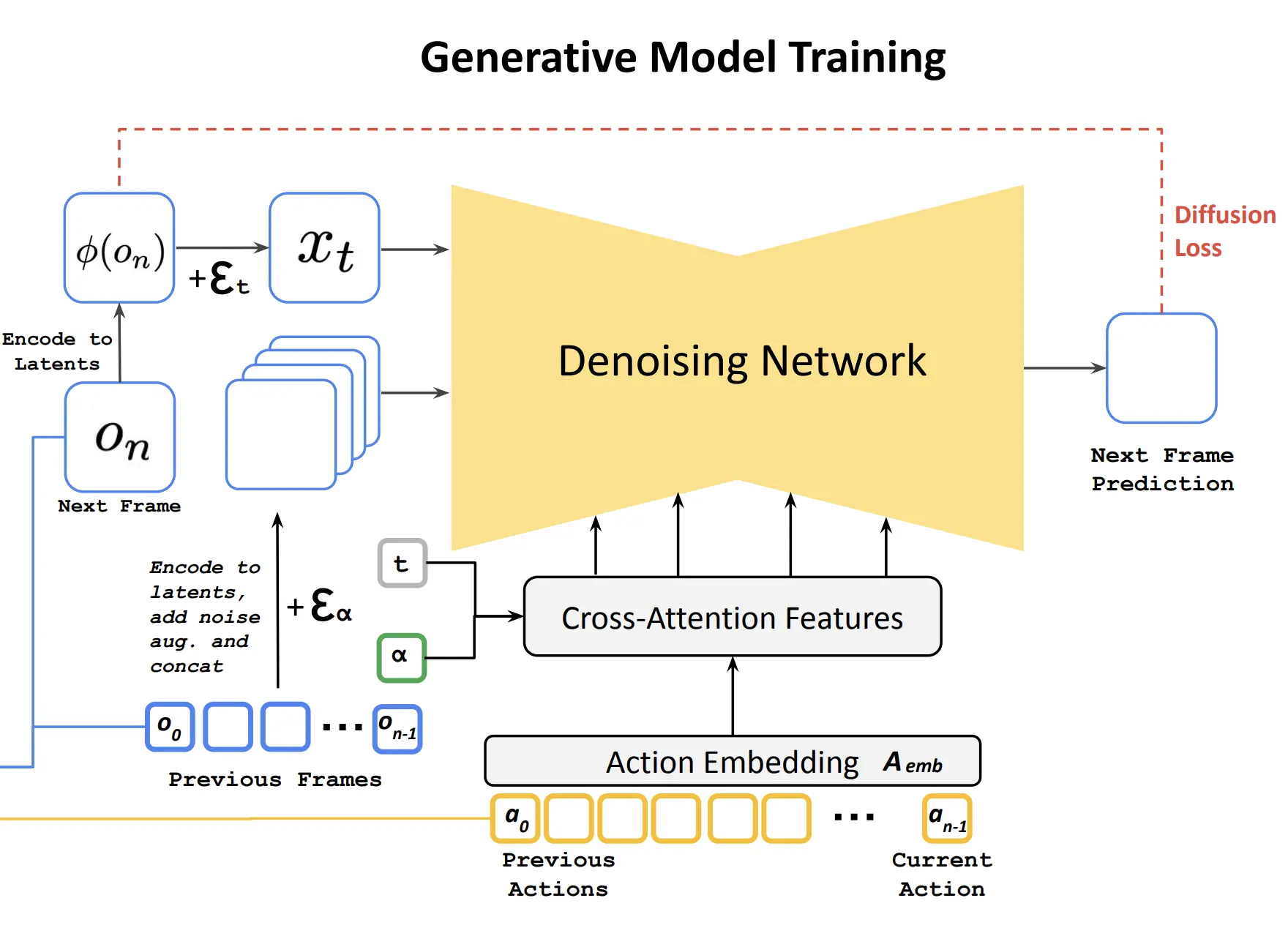
As a sidenote: ML researchers should really consider just dropping all the infodumping about their model architecture to an Appendix (or better yet, to runnable code) where they’ll clutter the article less and put in more effort into describing their experimental setups and scrutinizing results. I couldn’t care less about how they used ADAM to train a recurrent CNN on the Graph Laplacean if the experiments are junk or the results do not support the conclusions.
The human rater experiment (IMO the most important one for a human-interfacing software tool) is described from setup to a results in a single paragraph.


Those actions described in that section are generated by an RL agent, used only for training. For the prediction and therefore results they still either check for aggregate metrics (which must use synthetic data in order to get enough of it), or do the MTurk comparison that generated up to 3 second clips which could in theory be created from real-time user input but since they have corresponding ground-truth frames it must at best be generated from sampled user input from a real gameplay session.
The clips they show on the YouTube video seem to have some interactive input, but the method for creating those is not described in the paper. So I suppose it is possible that there’s some degree of real time user input, but it’s not clear that it is in fact what’s happening there.
As a sidenote: ML researchers should really consider just dropping all the infodumping about their model architecture to an Appendix (or better yet, to runnable code) where they’ll clutter the article less and put in more effort into describing their experimental setups and scrutinizing results. I couldn’t care less about how they used ADAM to train a recurrent CNN on the Graph Laplacean if the experiments are junk or the results do not support the conclusions.
The human rater experiment (IMO the most important one for a human-interfacing software tool) is described from setup to a results in a single paragraph.