
{kind=link}
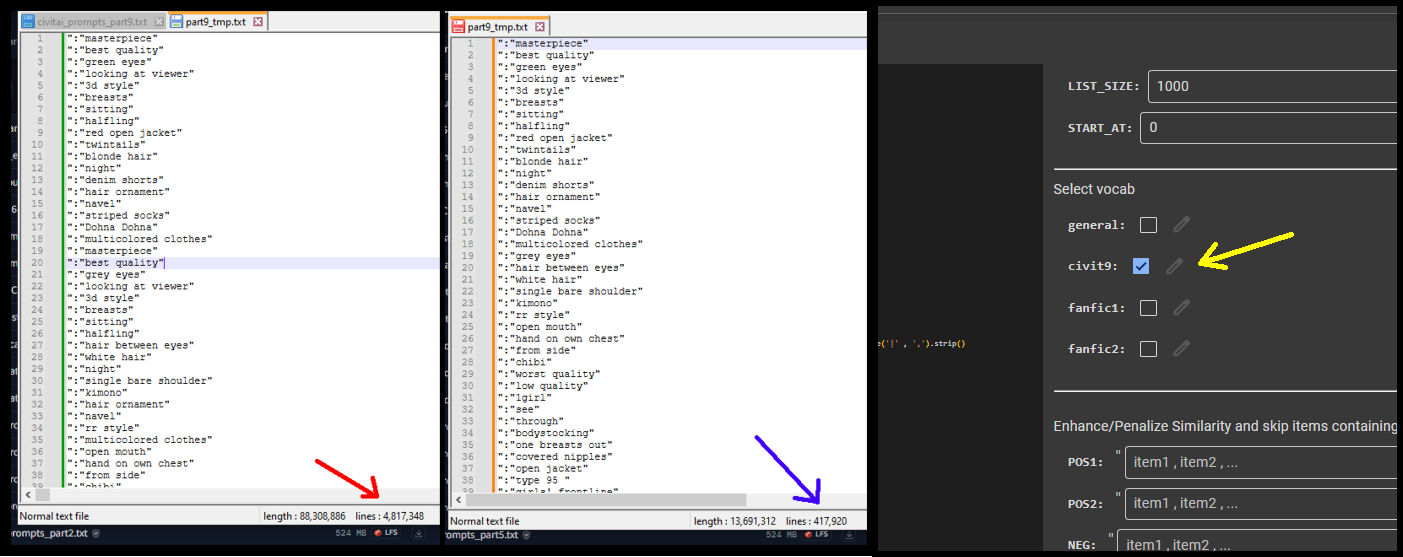
Image shows list of prompt items before/after running ‘remove duplicates’ from a subset of the Adam Codd huggingface repo of civitai prompts: https://huggingface.co/datasets/AdamCodd/Civitai-2m-prompts/tree/main
The tool I’m building “searches” existing prompts similiar to text or images.
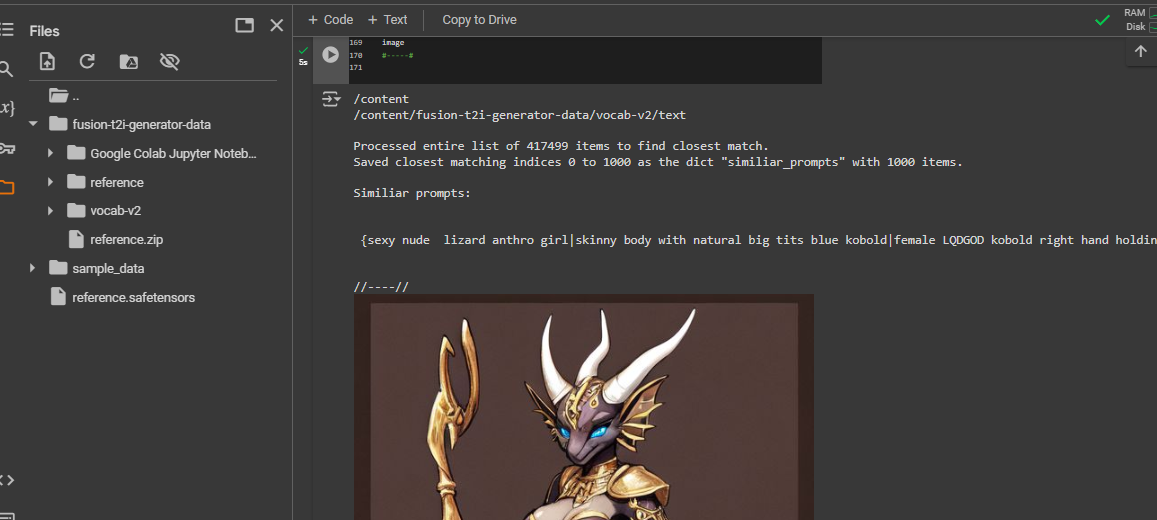
Like the common CLIP interrogator , but better.
Link to notebook here: https://huggingface.co/datasets/codeShare/fusion-t2i-generator-data/blob/main/Google Colab Jupyter Notebooks/fusion_t2i_CLIP_interrogator.ipynb
For pre-encoded reference , can recommend experimenting setting START_AT parameter to values 10000-100000 for added variety.
//—//
Removing duplicates from civitai prompts results in a 90% reduction of items!
Pretty funny IMO.
It shows the human tendency to stick to the same type of words when prompting.
I’m no exception. I prompt the same all the time. Which is why I’m building this tool so that I don’t need to think about it.
If you wish to search this set , you can use the notebook above.
Unlike the typical pharmapsychotic CLIP interrogator , I pre-encode the text corpus ahead of time.
//—//
Additionally , I’m using quantization on the text corpus to store the encodings as unsigned integers (torch.uint8) instead of float32 , using this formula:
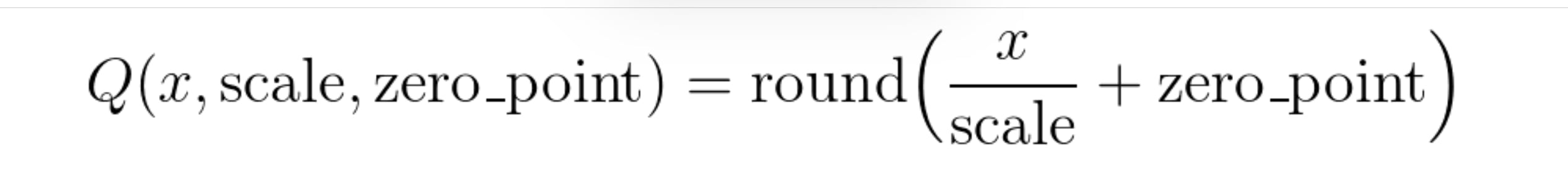
For the clip encodings , I use scale 0.0043.
A typical zero_point value for a given encoding can be 0 , 30 , 120 or 250-ish.
The TLDR is that you divide the float32 value with 0.0043 , round it up to the closest integer , and then increase the zero_point value until all values within the encoding is above 0.
This allows us to accurately store the values as unsigned integers , torch.uint8 .
This conversion reduces the file size to less than 1/4th of its original size.
When it is time to calculate stuff , you do the same process but in reverse.
For more info related to quantization, see the pytorch docs: https://pytorch.org/docs/stable/quantization.html
//—//
I also have a 1.6 million item fanfiction set of tags loaded from https://archiveofourown.org/
Its mostly character names.
They are listed as fanfic1 and fanfic2 respectively.
//—//
ComfyUI users should know that random choice item1 exists as a built in-feature.

//–//
Upcoming plans is to include a visual representation of the text_encodings as colored cells within a 16x16 grid.
A color is an RGB value (3 integer values) within a given range , and 3 x 16 x 16 = 768 , which happens to be the dimension of the CLIP encoding
EDIT: Added it now

//—//
Thats all for this update.